Counterfactual Reasoning and Environment Design for Active Preference Learning
Yi-Shiuan Tung, Bradley Hayes, and Alessandro Roncone
University of Colorado Boulder
Workshop Paper PDF
Overview

Robots deployed in the real world must align their behaviors with human preferences—whether balancing speed and safety in delivery tasks or adapting routes based on distance, time, and terrain. But those preferences are hard to predefine and differ across users.
Active Preference Learning (APL) helps robots learn these preferences by asking users to compare and rank trajectories. To improve sample efficiency, we present the human with trajectory pairs that maximize information gain [1]. The objective minimizes the difference between the entropy of the reward distribution (\(H(w)\)) before and after getting human input (\(I\)).
\(\begin{equation} \max_{\xi_A, \xi_B} f(\xi_A, \xi_B) = \max_{\xi_A, \xi_B} H(\mathbf{w}) - \mathbb{E}_{I}[H(\mathbf{w} | I)] \end{equation}\).
To make the optimization tractable, prior work use a pre-generated set of trajectories from random rollouts [1] or rollouts from a replay buffer [2] to find trajectory pair that optimizes information gain. However, this is sample inefficient for long-horizon tasks because the number of possible trajectories grow exponentially as the number of horizon increases. For robot routing, we also have to query the human for preferences in different environments or scenarios to enable generalization. Therefore, we include the environment parameters as optimization variables.
We propose CRED, a method that improves preference learning by:
- Using Counterfactual Reasoning to generate queries with trajectories that represent different preferences.
- Performing Environment Design to create “imagined” environments that better elicit informative preferences.
CRED significantly improves sample efficiency and generalization across both simulated GridWorld and OpenStreetMap navigation.
Method
1. Counterfactual Reasoning
When asking humans for preferences, we hypothesize that the trajectories should represent different preferences. To do that, CRED samples potential human reward functions from the current Bayesian belief over weights (w), and generates trajectories that would be optimal if those weights were true. It then evaluates pairs of these counterfactual trajectories to find the most informative preference queries—those that maximize Eq. 1.
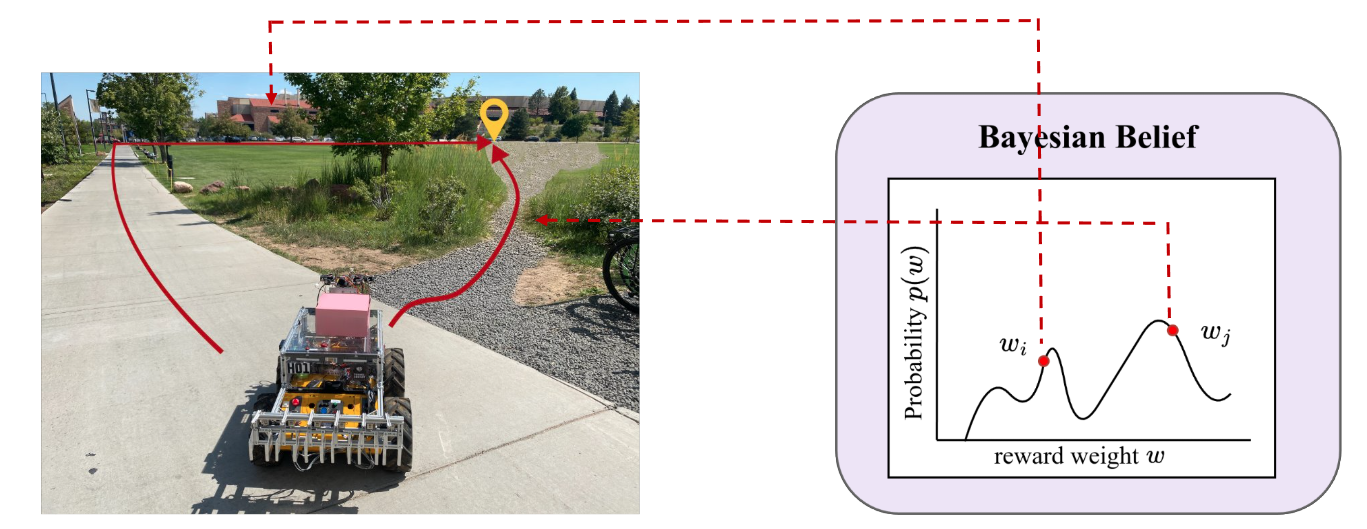
2. Environment Design
The environment affects which preferences can be expressed. For example, distinguishing between preferences for “paved vs. gravel” requires an environment with both terrains.
CRED uses Bayesian Optimization to find environment configurations that maximize the informativeness of queries. In practice, this means modifying terrain layouts or edge attributes (e.g., road slope or elevation) to elicit more useful feedback. Bayesian optimization uses a Gaussian process to guide its search, reducing the number of evaluations of Eq. 1. Here, \(F\) is Eq. 1 but includes environment parameters \(\theta_E\) as optimization variables.
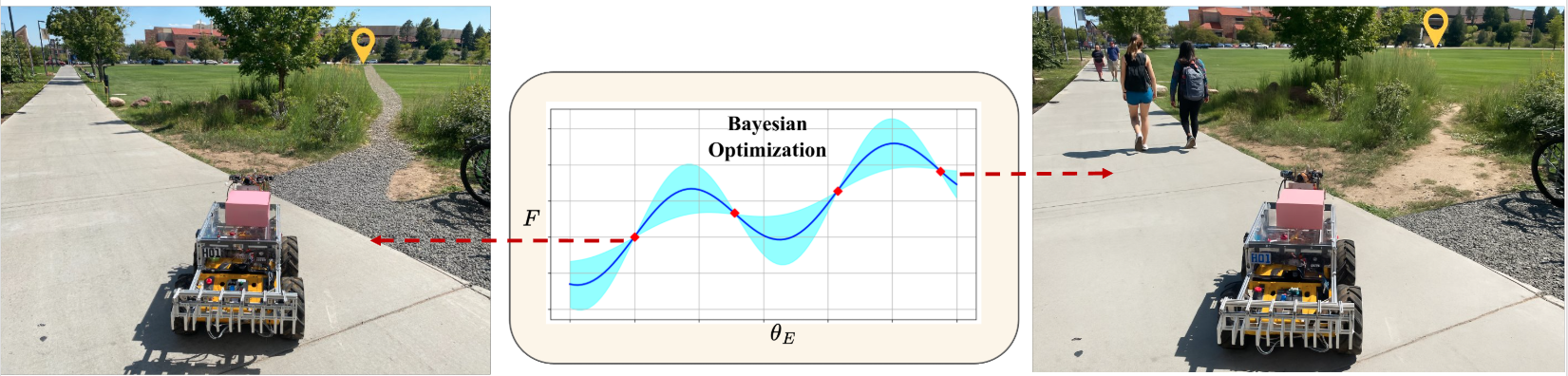
Experiments
We evaluate CRED in two domains:
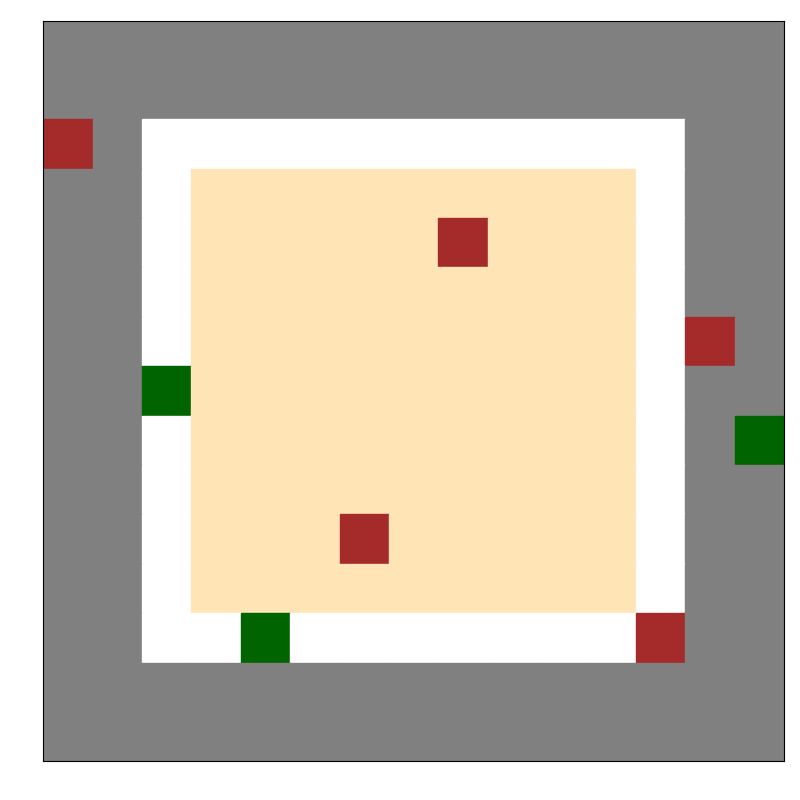
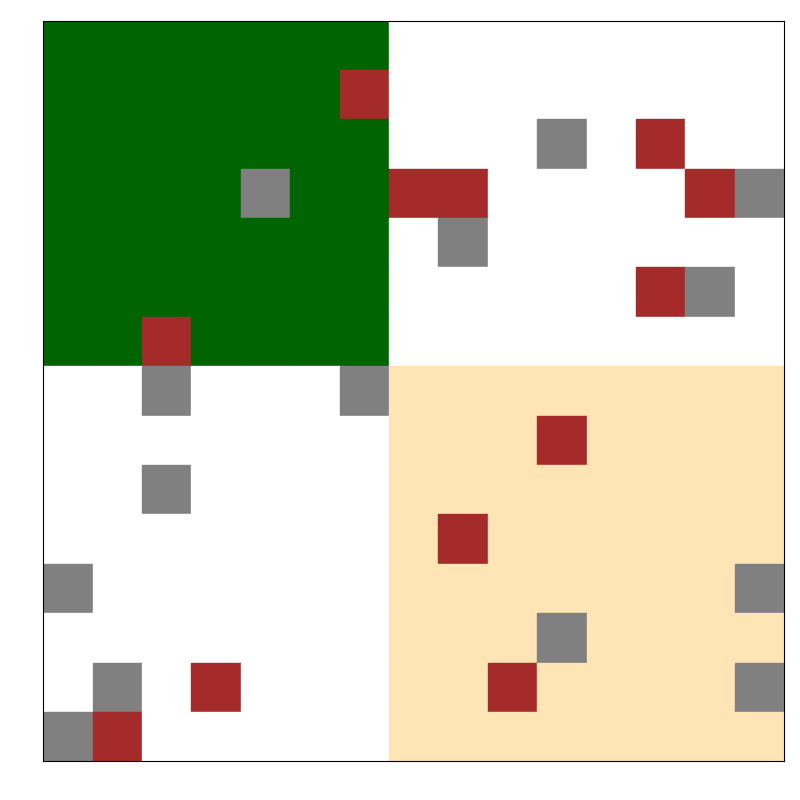
GridWorld Navigation
A 15×15 terrain-based environment with brick (red), gravel (grey), sand (yellow), grass (green), and paved (white). The goal is to move from the top left corner to the bottom right corner. For environment design, we first compress the 15x15 grid to a 5 dimensional vector using variational autoencoder.



OpenStreetMap Routing
We use OpenStreetMap to extract nodes representing intersections and edges representing streets. We evaluate the algorithm’s ability to learn preferences for distance, time, and elevation (+/-). For environment design, we modify edge attributes such as traversal time (i.e. traffic) and elevation and evaluate generalization to new street networks.
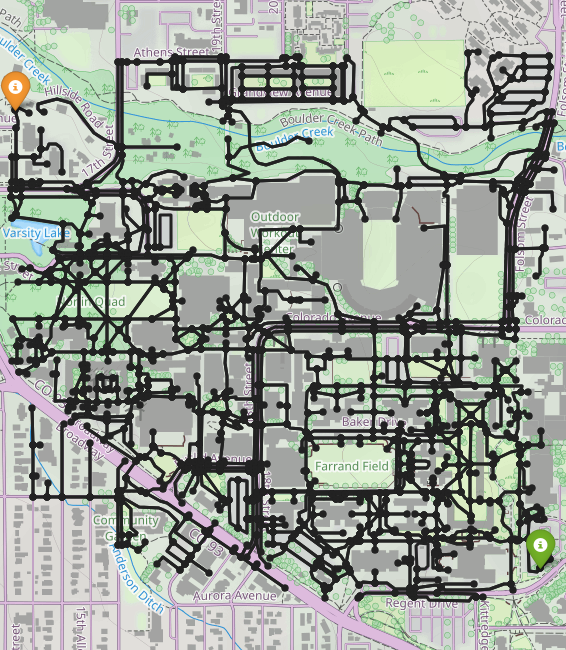
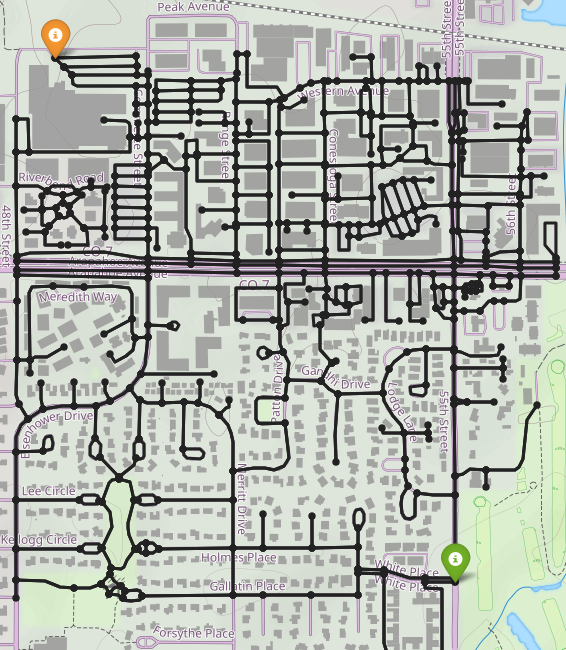
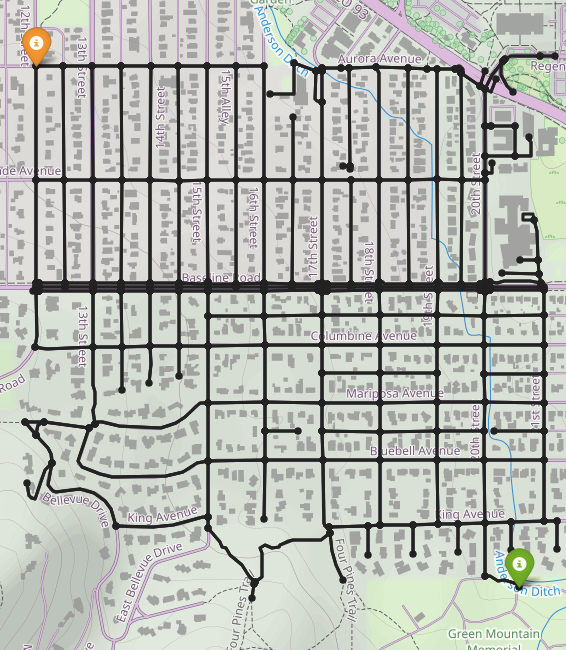
Baselines
We compare CRED to:
- RR (Random Rollouts): Pre-generated set of trajectories through random rollout [1].
- MBP (Mean Belief Policy): Uses the mean of the belief over rewards as the best guess and perform rollouts with policy trained on the reward [3].
- CR (Counterfactual Reasoning only): Ablation of CRED without environment design.
- MBP + ED: Mean Belief Policy combined with environment design.
Key Results
👀 Qualitative Results
While Mean Belief Policy [3] (left) can generate trajectories with different features, the trajectories are very similar. Counterfactual reasoning (middle) generates trajectories that better resemble different preferences. With environment design (right), we can query the human for feedback in different environments.
🔍 Higher Information Gain
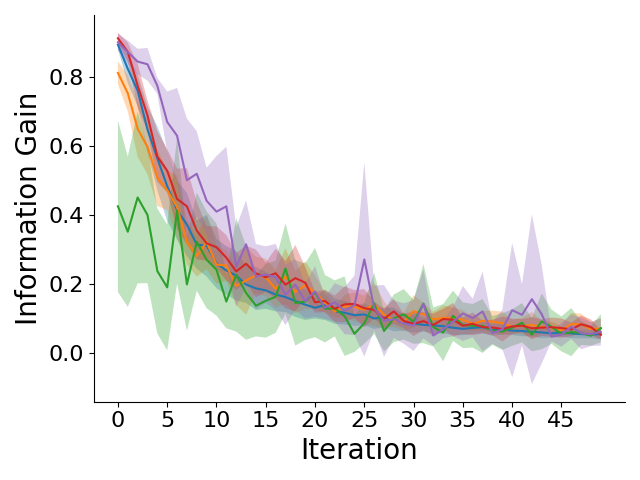
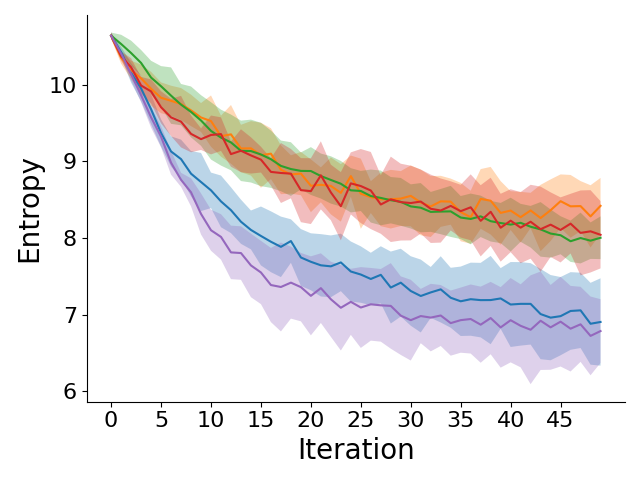
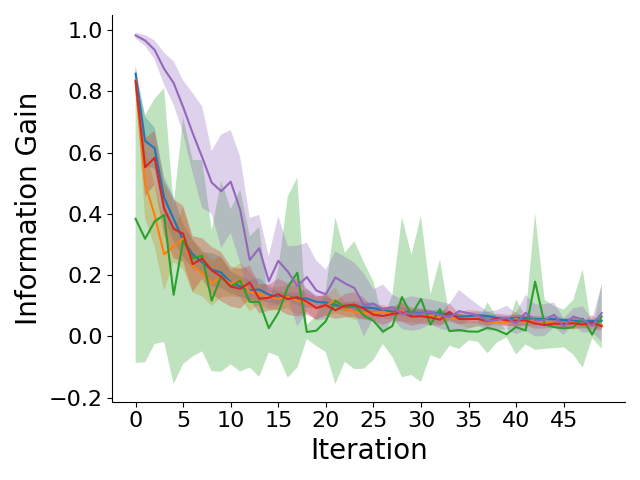
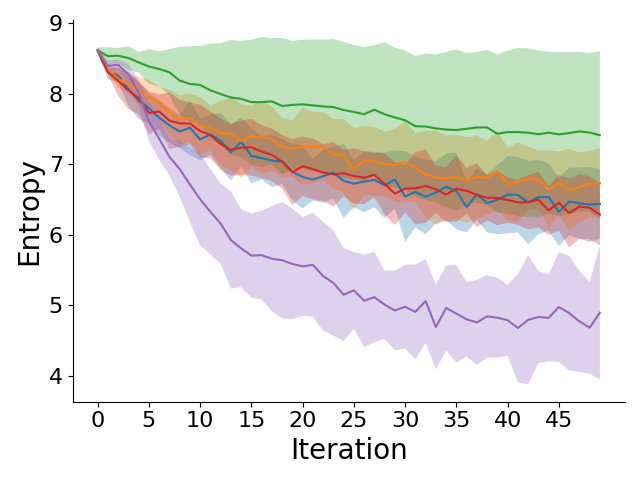
Left to right: GridWorld information gain, entropy of belief over reward weights, OpenStreetMap information gain, and entropy of belief over reward weights across different iterations of querying the human for feedback. CRED generates more informative preference queries early on, resulting in lower entropy of the belief over rewards.
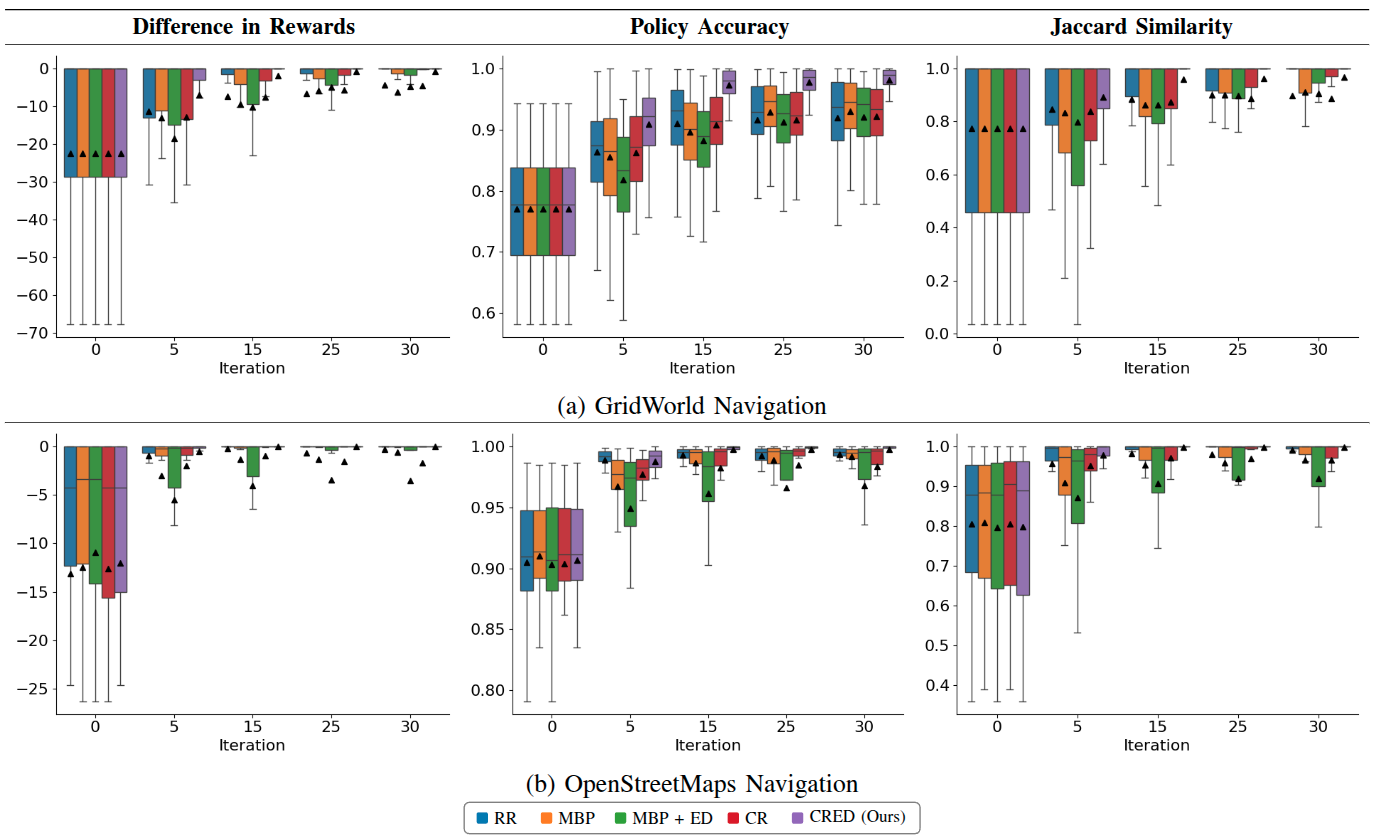
✅ Higher Generalization
CRED-trained policies perform better in unseen environments, demonstrating faster convergence and higher rewards and policy accuracy.
Conclusion
We introduce CRED for active preference learning which improves the sample efficiency and generalization of the learned reward functions. Counterfactual reasoning generates queries with trajectories that better resemble different reward functions. By using environment design, we can jointly optimize the environment and query generation, enabling the ability to query the human in different environments.
Acknowledgments
Thanks to Dusty Woods for help with visualizations and figure editing.
References
[1] Biyik, E., Palan, M., Landolfi, N. C., Losey, D. P., & Sadigh, D. (2020). Asking easy questions: A user-friendly approach to active reward learning. CoRL.
[2] Lee, K., Smith, L. M., & Abbeel, P. (2021). PEBBLE: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. ICML.
[3] Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. NeurIPS.
Contact
Questions or collaboration ideas?
📧 yi-shiuan.tung@colorado.edu
Enjoy Reading This Article?
Here are some more articles you might like to read next: